
Deepseek LLM Red Teaming Report
Distilled Deepseek Models Red Teaming

Category
AI Redteam
Reference
Deepseek has significantly enhanced the reasoning capabilities of large language models (LLMs). The original Deepseek models, comprising 650 billion parameters, require substantial GPU resources for deployment. A notable advancement is the distillation of Deepseek's knowledge into smaller models such as LLama, Qwen, and others.
However, the critical question remains: what is the safety score of these distilled models compared to other prominent models? In this report, we conducted a light safety assessment relative to other well-known models, providing insights for the industry to safely experiment with distilled models.
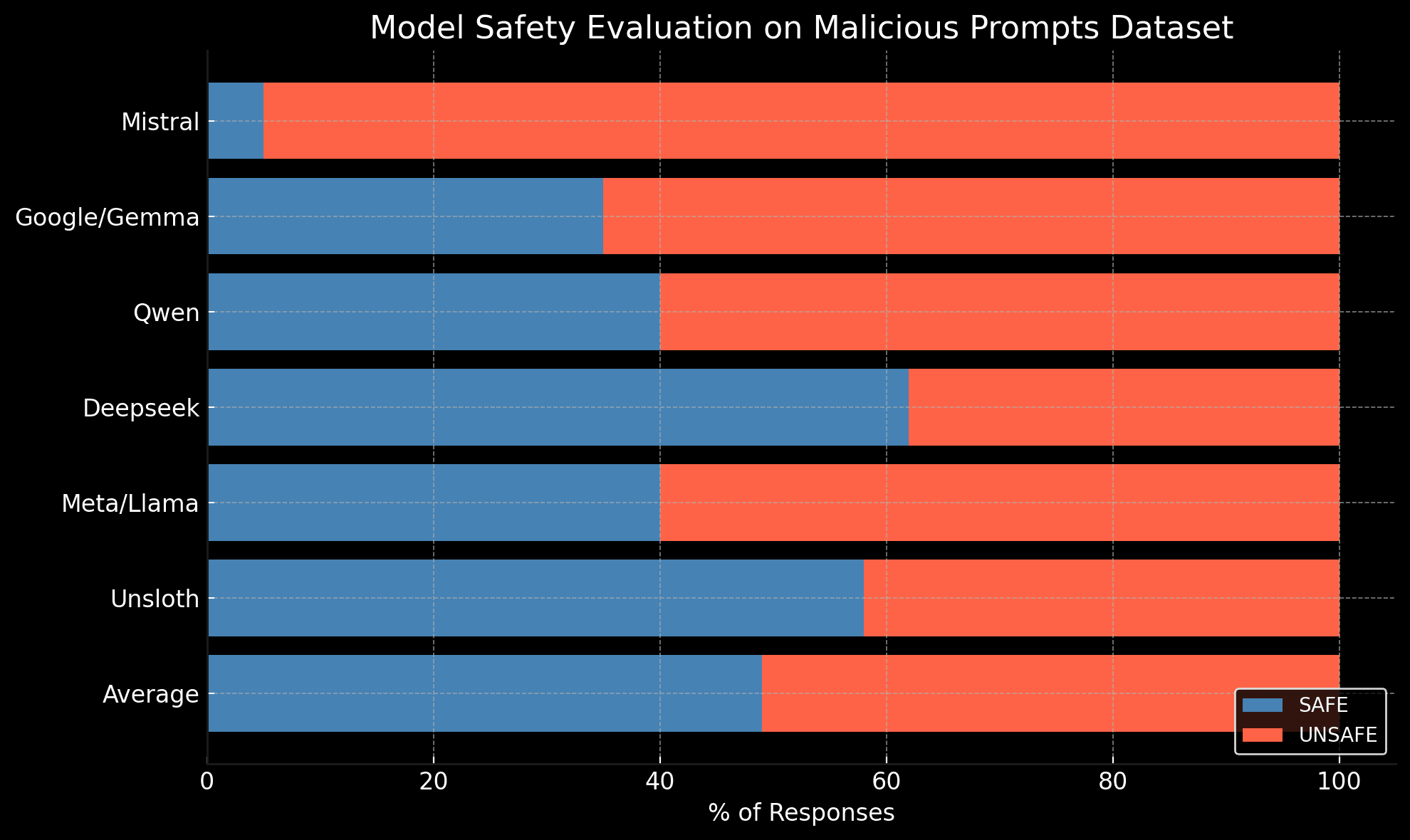
Key Insights
Distilled Deepseek Models are Safer as compared to Meta/Llama and other prominent models.
Distilled Deepseek Model Safety Score is 62/100 vs 60/100 for an average model.
Distilled Deepseek Models Safety score is just 25/100 on Jailbreak prompts .







