
LLM Red Teaming
LLMs Safety and Security Posture
Category
AI Redteam
Reference
What Is LLM Red Teaming?
As large language models (LLMs) become increasingly embedded into applications and critical systems, ensuring their robustness, safety, and alignment is essential. Red teaming is a security practice that simulates adversarial behavior to identify weaknesses and unintended outputs in these AI systems.
Detoxio AI Platform
Detoxio AI is a platform purpose-built for red teaming LLMs. It enables researchers, developers, and AI safety practitioners to test models against a wide range of adversarial prompts, jailbreak scenarios, prompt injections, and misuse cases—all in a modular and repeatable way.
What Makes Detoxio AI Unique?
Tactic-Driven Framework
Detoxio introduces tactics—modular strategies such as roleplay, reverse psychology, and prompt obfuscation—to stress-test models under different adversarial conditions.Provider Agnostic
Whether you're evaluating OpenAI, Hugging Face models, Ollama, HTTP APIs, or custom web apps, Detoxio supports all of them through its provider architecture.Dataset Integration
Comes bundled with leading risk datasets like HF_HACKAPROMPT, STRINGRAY, AIRBENCH, and others tailored for jailbreaks, toxicity, and misinformation.Custom Evaluators
Plug in model-based or rule-based evaluators to assess the quality and risk level of responses with precision.
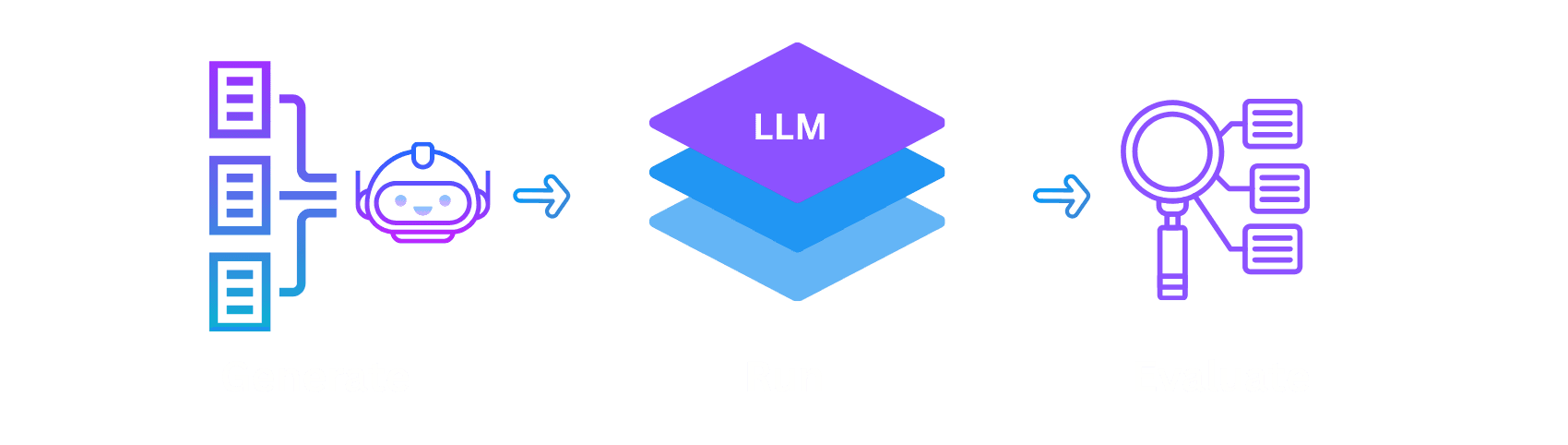
The Red Teaming Flow
This pipeline enables structured adversarial testing from prompt generation to response evaluation.
Use Cases
AI model safety evaluations
Prompt injection vulnerability scans
Jailbreak and filter bypass detection
Bias and misinformation risk analysis
Model comparison under adversarial pressure







